Scraping Glassdoor: How to Extract Glassdoor Job Data to a CSV file?
If you are looking for an efficient, free way to extract job postings from Glassdoor and organize them in a CSV file, this article has you covered.


We will guide you through creating a tool that scrapes job listings on Glassdoor based on your search criteria, which will enable you to analyze data across different platforms seamlessly. Also, we will discuss how to scrape Glassdoor data efficiently using Python by highlighting how easy it is to use several free libraries available in creating scrapers.
Data analysis can inform decision-making to the benefit of employers and job seekers. This free, practical solution is for job data collection for lead generation, market research, and competitive tracking.
By the end, you will have a full Glassdoor job scraper with hands-on usable code that allows you to instantly aggregate and export job data directly into a CSV file.
Choosing the Best Method and Tool for Scraping Glassdoor
You can explore different ways to scrape data from Glassdoor, such as manual scraping using Python with Selenium, APIs, or no-code tools.
Manual scraping is therefore flexible but often time-consuming. APIs give a structured flow of data, overcoming most obstacles and assuring a very fast approach. For people who don't know how to program, there are some easy-to-use tools for data extraction, such as Mantiks, Octoparse or ParseHub.
For a more in-depth guide to job scraping, see our complete guide to scraping job data effectively.
Scrape Glassdoor Job Postings Data Using a Free API Tool
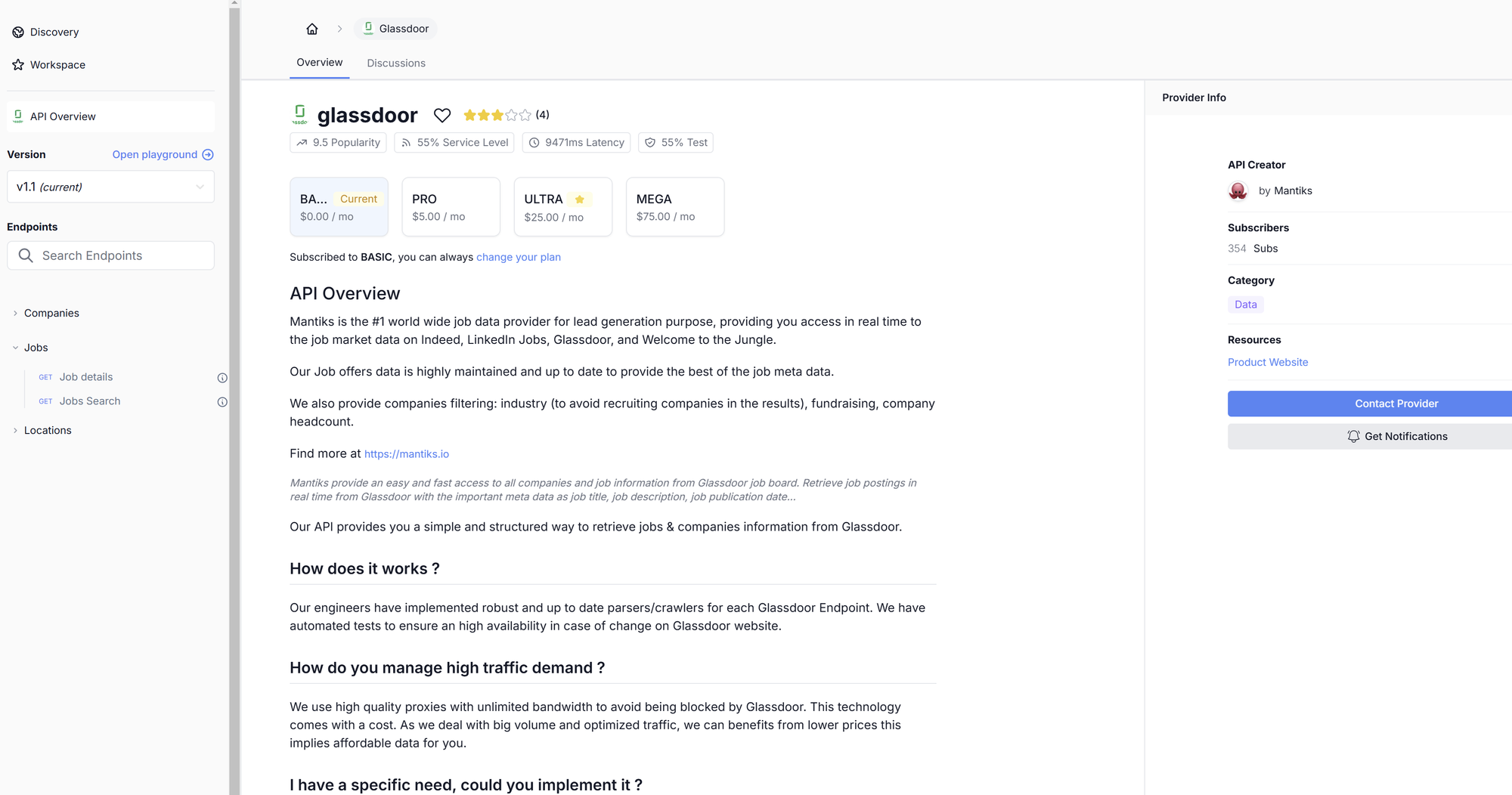
We will be using the free Mantiks API on RapidAPI to scrape salary data on Glassdoor that includes job titles, company names, salaries, and required skills.
For those who need more data, additional access is very cheap.
Here are the steps to guide you in creating a Glassdoor scraper that collects job postings based on your search criteria.
Step 1: Setting Up the Environment and API Registration
1.1 Prerequisites
We recommend checking out our step-by-step tutorial on how to scrape job posts with Python for foundational knowledge. You will understand why building a Glassdoor scraper from scratch, without an API, is rather daunting.
While the API handles most data retrieval and processing, you’ll still need to make a request to get Glassdoor job data and use Pandas to export results to CSV.
Ensure your environment and libraries are set up by following Step 1 in our beginner’s guide to scraping job postings with Python.
1.2 Register with RapidAPI
To leverage this API do the following:
- API page: Go to the Glassdoor API on RapidAPI.
- Sign Up / Login: New to RapidAPI? Click "Sign Up."
Otherwise, log in using Google, GitHub, or by entering your email and password.
- Subscribe to the API: by clicking Subscribe after logging in to the API page and select the free plan.
- Get your API key: Once subscribed, an API key will be provided.
This is the most important and information that shall be used in making requests.

Once you have the API key, you are good to go for setting up parameters to begin searching with the Glassdoor scraper.
Step 2 : Configuring Glassdoor Search Parameters to get Job data
You shall set up search parameters, after which you may extract any job posting from Glassdoor. It is pretty much the same as setting filters were you use to browse directly from Glassdoor's website.
- Select the Job Search Endpoint: On the left, click on the Job Search endpoint to reveal its options to fetch job postings.
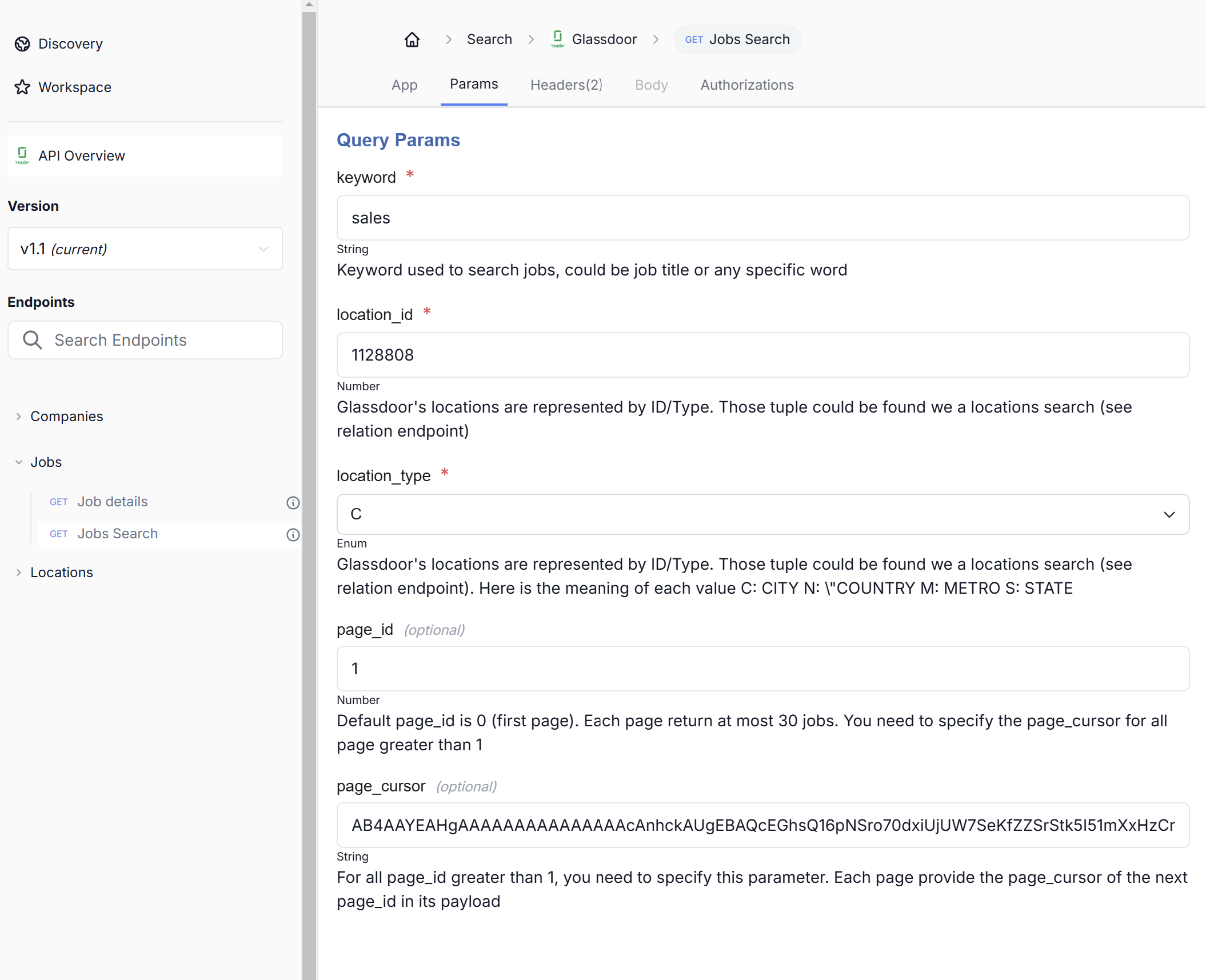
- Open the "Params" Tab: Once Job Search has been selected, under that, click on "Params" tab to set up different search parameters.

2.1 Set Up Your Search Parameters
Here are some of the most helpful settings to personalize your job search:
- keyword: Required, keywords that filter job listings. For example, we use "sales".
- location_id: (Required) ID representing the location for the search. In this example, "1128808" is used.
- location_type: (Required) Type of location ID, represented as "C" for city, "N" for country, "M" for metro, and "S" for state. Here, it is set to "C" for city.
- page_id: (Optional) Page number for pagination of results. If omitted, it defaults to the first page, which is "0".
- page_cursor: (Optional) Required for pagination beyond the first page. The page_cursor from the next page is provided in its payload.
2.2 Looking at the web scraping Code
Once selected, on the right-hand side of the screen, a sample code snippet will be automatically generated, given your parameters. The code below displays a simple Python API request in making the specified search setting.
2.3 Example code
Replace the value of "x-rapidapi-key" with your API key and update the parameters to your liking then save this code:
import requests
url = "https://glassdoor.p.rapidapi.com/jobs/search"
querystring = {"keyword":"sales","location_id":"1128808","location_type":"C","page_id":"1","page_cursor":"AB4AAYEAHgAAAAAAAAAAAAAAAcAnhckAUgEBAQcEGhsQ16pNSro70dxiUjUW7SeKfZZSrStk5I51mXxHzCrtp1Zt1Gox6xKANcdSbluwPnLv0Lxu3SFKh8C33qAPvr9HZT+BpC/K8wtBPaUAAA=="}
headers = {
"x-rapidapi-key": "f2797e5bfbmshc4ddbba52bf314fp1125a3jsnf27ac33ee975",
"x-rapidapi-host": "glassdoor.p.rapidapi.com"
}
response = requests.get(url, headers=headers, params=querystring)
print(response.json())2.4 Run the Code and Review the Job Details API Job listing data
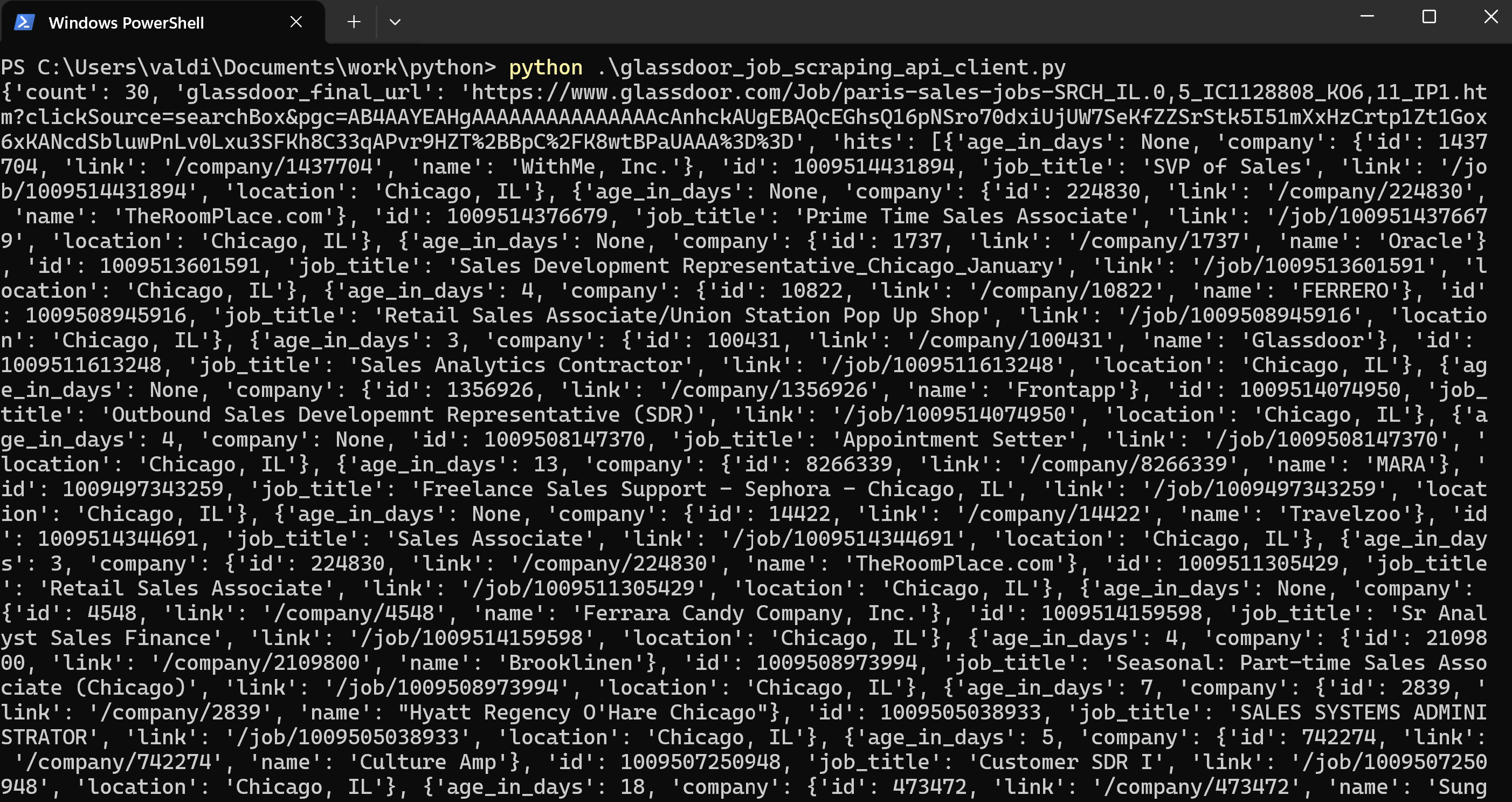
The above API call returned a JSON with the job listings matching your search parameters. Each listing show details on the job position, including glassdoor salary data.
This response contains:
Count of Jobs: Overall number of jobs in the response - each results page from Glassdoor returns 30 postings.
Job Details: Each job posting details the following:
- Company Name: This is the name of the company offering the job.
- Location: The city and state of the posting, i.e., "Chicago, IL".
- Title: Job title, such as "SVP of Sales" or "Sales Associate".
- Link: Link to the Glassboard posting of the job.
- Compensation: Provide the salary range if possible-minimum to maximum.
- Job Type: Shows whether it is a salaried or per-hour job.
- Posting Date: Age of the posting in days, if provided.
- Job ID: The unique number for each posting.
The API paginates job listings (with 30 listings per page here) so pagination would be handled through modification of the page_id parameter with the next_page_cursor of each response to retrieve additional job listings for the search.
Step 3: Managing Pagination to Collect All Job Listings and Export Data to CSV
To retrieve all job listings matching your search criteria, you’ll need to manage pagination effectively. The API returns results in pages, each containing 30 job listings, so you must update the page_id parameter for each subsequent page until all results are gathered. This process involves handling scraped data efficiently to ensure comprehensive coverage of available job listings.
The API response stores job listings under the hits key. For each page, we’ll extract data from this key, compile it into a list, and then convert it into a DataFrame for easier manipulation.
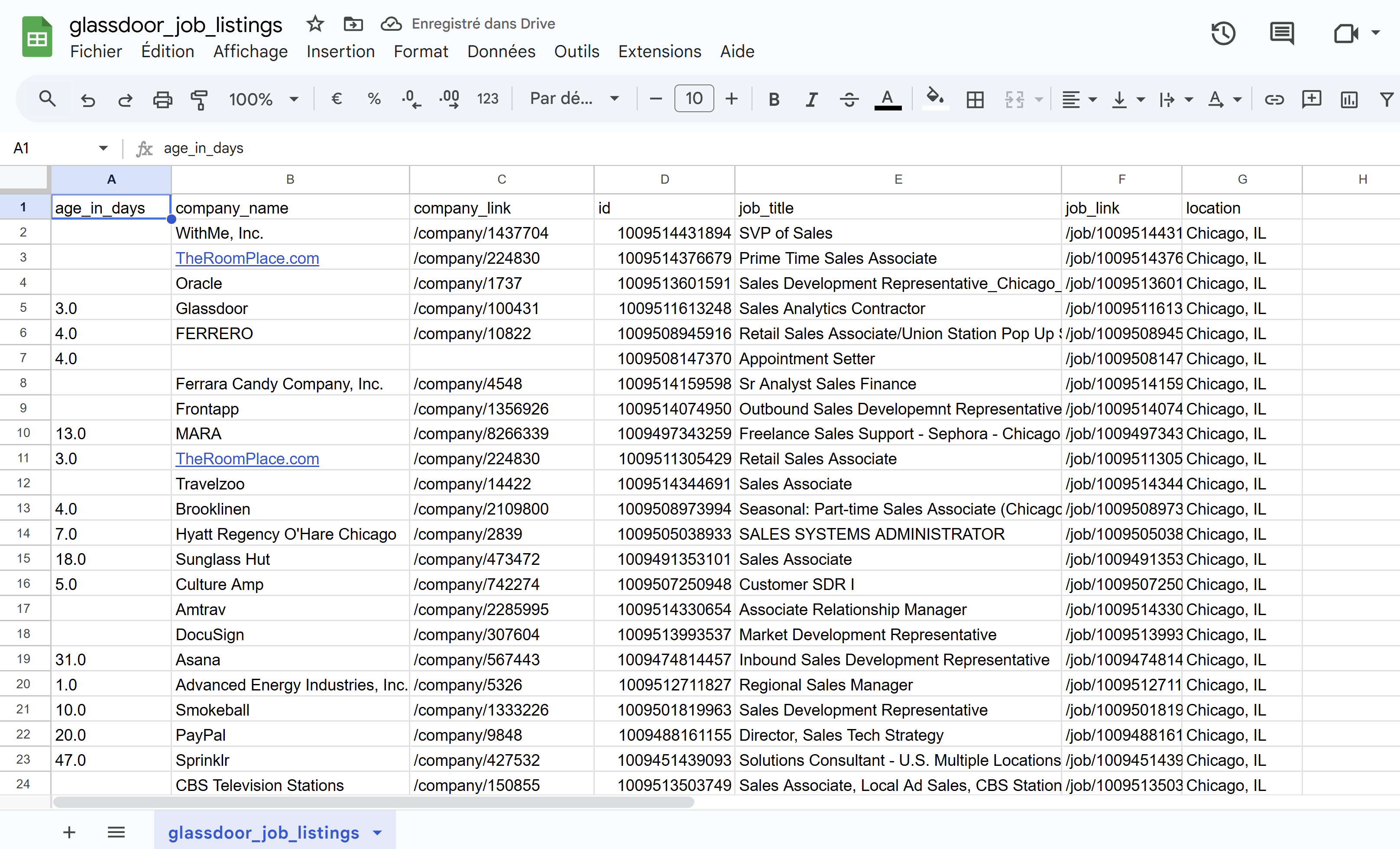
Finally, we’ll export the job data to a CSV file named glassdoor_job_listings.csv for convenient access and analysis.
Here’s the code for handling pagination and exporting Glassdoor job results:
import requests
import pandas as pd
# Set up the API endpoint and headers
url = "https://glassdoor.p.rapidapi.com/jobs/search" # Replace with the correct Glassdoor API URL
headers = {
"x-rapidapi-key": "f2797e5bfbmshc4ddbba52bf314fp1125a3jsnf27ac33ee975", # Replace with your API key
"x-rapidapi-host": "glassdoor.p.rapidapi.com"
}
# Define initial search parameters
query_params = {
"keyword": "sales",
"location_id": "1128808", # Location ID for your target area
"location_type": "C", # Location type, e.g., 'C' for city
"page_id": 1 # Start from the first page
}
# Initialize an empty list to store job data
all_jobs = []
# Loop through pages until no more data is returned
while True:
response = requests.get(url, headers=headers, params=query_params)
data = response.json()
# Check if there are job listings in the 'hits' field
if 'hits' in data and data['hits']:
for job in data['hits']:
# Check if 'company' exists and is not None, then extract relevant information
company_info = job.get("company", {})
job_data = {
"age_in_days": job.get("age_in_days"),
"company_name": company_info.get("name") if company_info else None,
"company_link": company_info.get("link") if company_info else None,
"id": job.get("id"),
"job_title": job.get("job_title"),
"job_link": job.get("link"),
"location": job.get("location"),
}
all_jobs.append(job_data) # Add the processed job data to the list
query_params["page_id"] += 1 # Move to the next page
# Update the page_cursor if provided for the next page
if 'next_page' in data and 'next_page_cursor' in data['next_page']:
query_params["page_cursor"] = data['next_page']['next_page_cursor']
else:
break # Stop if no more pages are available
else:
break # Stop if no more job listings are returned
# Convert the list of job data to a DataFrame and export to CSV
df = pd.DataFrame(all_jobs)
df.to_csv("glassdoor_job_listings.csv", index=False)
print(f"Total jobs retrieved: {len(all_jobs)}")
Step 4: Executing and Testing the Glassdoor Scraper
Once your scraper is built, it’s important toexecute and test it to ensure it functions correctly and extracts the desired data. Start by running the scraper on a small scale, such as a single job listing page or a limited set of pages. This initial test helps identify any issues or errors, ensuring the scraper works as expected.
After validating the scraper on a small scale, you can scale up the operation to extract data from multiple job listing pages or even the entire Glassdoor website.
To automate this process, consider using a scheduler or workflow management tool like Apache Airflow or Zapier. These tools can help you run the scraper regularly, ensuring that your data is always up-to-date and comprehensive.
Result and Conclusion
The Result
We were able to scrape all job postings matching our search criteria in our CSV file - 180 job offers!
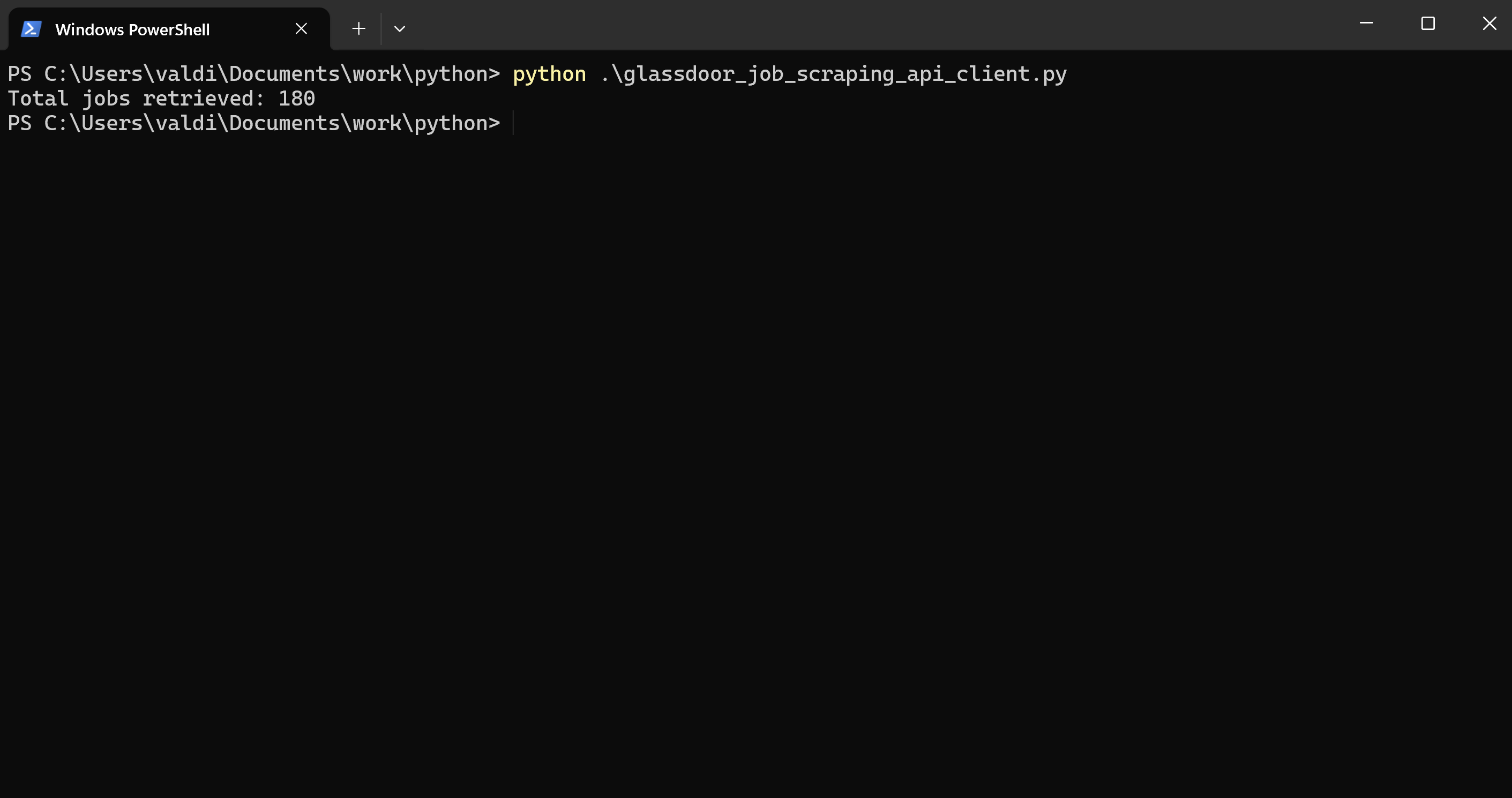
The code made 6 requests to gather these listings, since there are 30 job offers per page.
Final Thoughts
With this detailed guide, you now have a fully operational Glassdoor job scraper that can gather job listings based on specified criteria and export them directly into a CSV file. This setup greatly simplifies lead generation, market analysis, and competitive tracking. By utilizing web scraping Glassdoor, you can extract valuable job and salary data, aiding in formulating hiring strategies and understanding market trends.
As your data requirements grow, you can easily adjust or scale this setup, making it a flexible solution for a wide range of job data applications.
For a more advanced approach, consider the next logical step: collecting contact information for hiring managers associated with these listings.
Happy scraping, and feel free to explore additional configurations or parameters to further customize your Glassdoor job scraper!
Curious about Job board scraping ? Our guide walks you through the essential methods and tools to help you get started.
FAQ on Scraping Glassdoor
Is it legal to scrape a Glassdoor?
Scraping public job and company data is generally permitted by law, even if Glassdoor's Terms of Service discourage it. Using APIs, when available, can help ensure compliance.
How to scrape Glassdoor salaries?
To scrape salary data from Glassdoor, focus on job listing data that includes compensation details. You can use tools like Python with libraries such as BeautifulSoup or Scrapy, but be mindful of ethical and legal guidelines.
How to extract reviews from Glassdoor?
Glassdoor company reviews, which provide insights from current and former employees, can be extracted using similar techniques.
How to scrape Glassdoor with Python?
You can scrape Glassdoor with Python using libraries like BeautifulSoup and Requests. For advanced scraping of job listing data or company reviews, consider using Scrapy or Selenium for navigating dynamic content.
About the author

Alexandre Chirié
CEO of Mantiks
Alexandre Chirié is the co-founder and CEO of Mantiks. With a strong engineering background from Centrale, Alexandre has specialized in job postings data, signal identification, and real-time job market insights. His work focuses on reducing time-to-hire and improving recruitment strategies by enabling access to critical contact information and market signals.