Scraping Indeed: How to Extract Indeed Job Data to a Csv file?
If you’re seeking an easy, cost-free way to scrape job postings from Indeed and organize them in a CSV file, this step-by-step guide is for you.


We’ll walk you through building a tool that extracts Indeed job listings based on specific search criteria, allowing you to efficiently analyze data from various platforms.
Data analysis is crucial for decision-making, benefiting both employers and job seekers by providing valuable insights. This practical, free solution simplifies scraping for lead generation, market analysis, and competitive tracking.
By the end, you’ll have a fully functional Indeed job scraper with ready-to-use code that lets you instantly gather and export the job data you need—directly into a CSV file.
Which Method and Tool to Choose for Scraping Indeed?
To scrape job listing data on Indeed, you will be considering the main options of doing it manually using Python and Selenium, APIs, or no-code tools.
Manual scraping is flexible but time-consuming; it has its limitations. APIs guarantee a streamlined, structured flow of data, bypassing most obstacles to give the fastest approach. One can even collect the relevant data without any coding skills using tools such as Octoparse, ParseHub, or Mantiks.
To view the complete job scraping methods overview, explore effective ways to gather job data with our complete guide.
Scrape Indeed job postings data using a free API Tool
We will use the free Mantiks API available on RapidAPI to get the job data from Indeed, including job titles, company names, salaries, and skills.
The following steps will help you to create an Indeed scraper that scrapes the job postings according to your search criteria.
Step 1 : Setting Up the Environment and API Registration
1.1 Prerequisites
We advise you to go through our step-by-step tutorial on scraping job posts using Python, as it casts foundational knowledge and also explains why creating an Indeed scraper from scratch without an API is complicated.
While the API will handle most of the data retrieval and processing, you’ll still need to make a request to get the Indeed job data and use Pandas to export the results to CSV.
So before starting, make sure your environment and libraries are set up by following Step 1 of our how to scrape job postings using Python Beginner's guide.
1.2 Register to Rapid API
To start using the API, follow these steps:
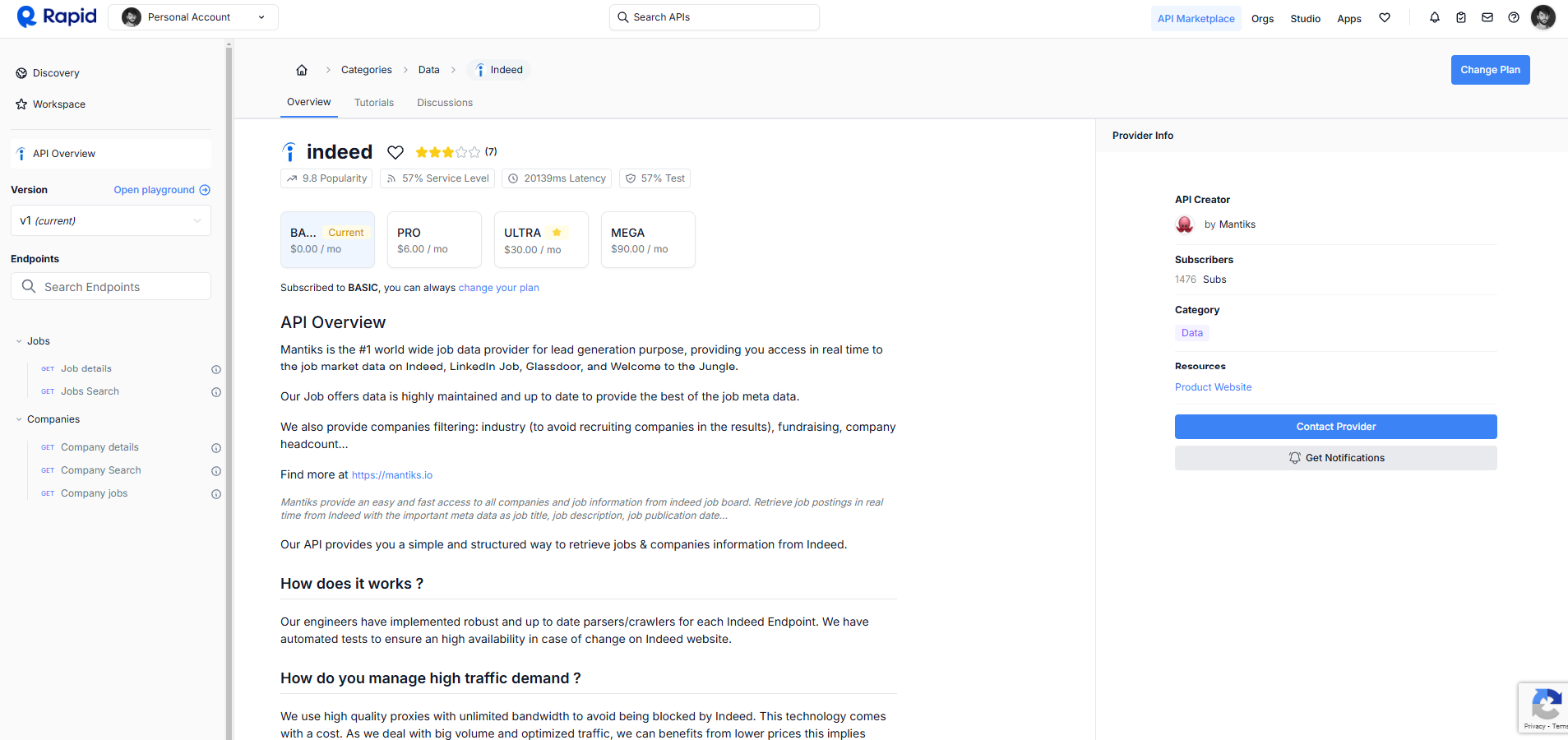
- Go to the API Page: Visit the Indeed API on RapidAPI.
- Sign Up or Log In: If you are a new user to RapidAPI, click "Sign Up"; otherwise, if you already have an account, click "Log In". You can easily register using Google, GitHub, or by typing your email and password.
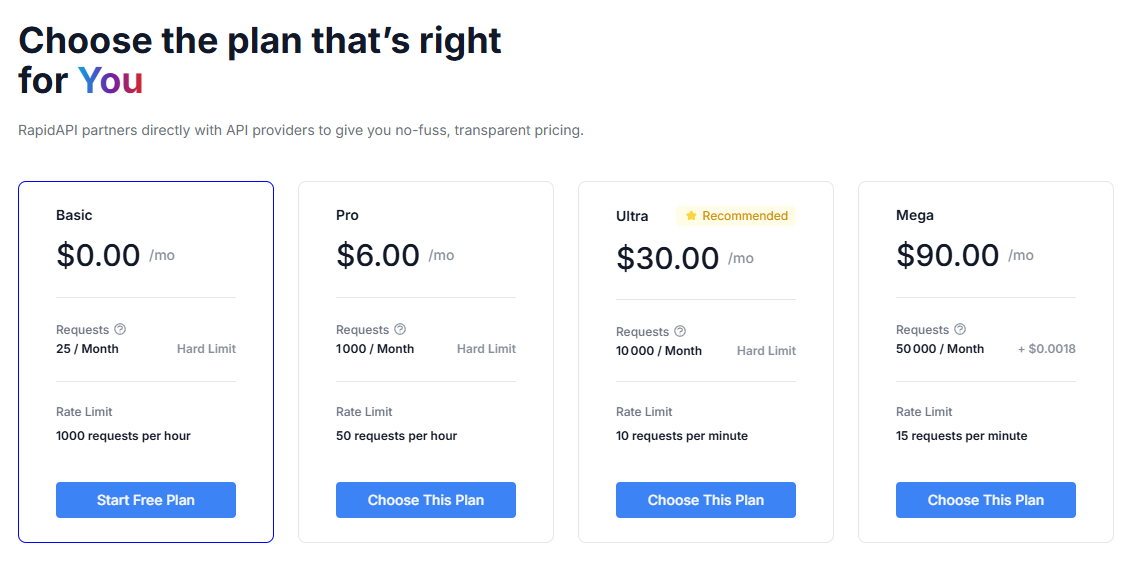
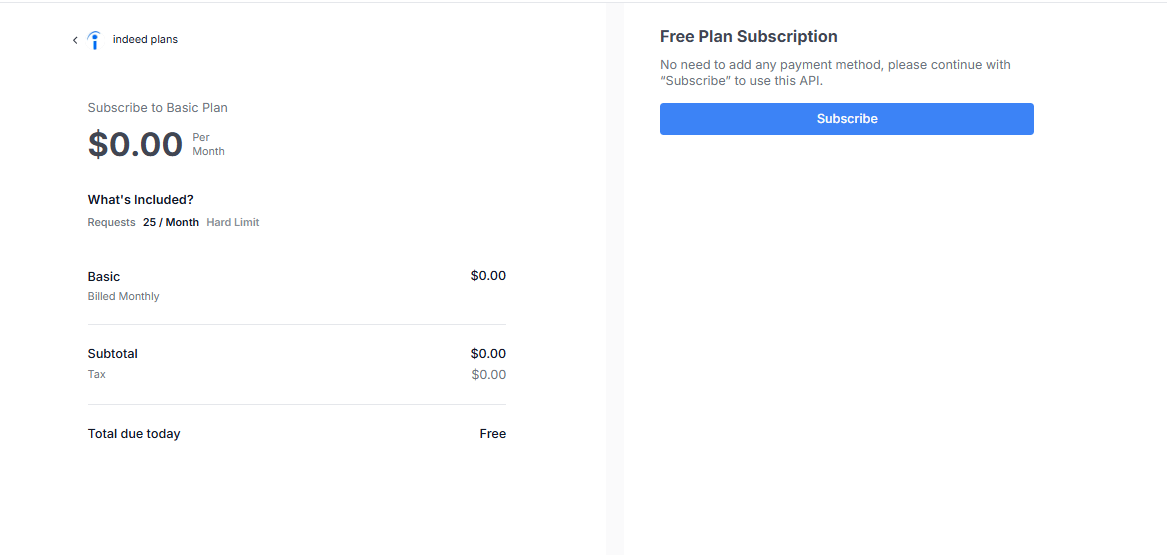
- Subscribe to the API: Sign in, then on the API page there is a button to click for subscribe, select free plan which has 25 requests per month (no credit card is required).
- Get Your API Key: Once subscribed, you'll receive a unique API key. An API key is required in order to make request; hence, it needs to be kept safe.

With your API key, you're good to go to set up your search parameters and start using Indeed Scraper.
Step 2 : Configuring Search Parameters to Retrieve Relevant Job Listings
You need to configure the search parameters in order to begin extracting job postings from Indeed. This is the same as setting filters if you were to browse Indeed's website directly. Here is how to do it:
- Select the Job Search Endpoint: On the left side, select the Job Search endpoint to access the options for retrieving job listings.
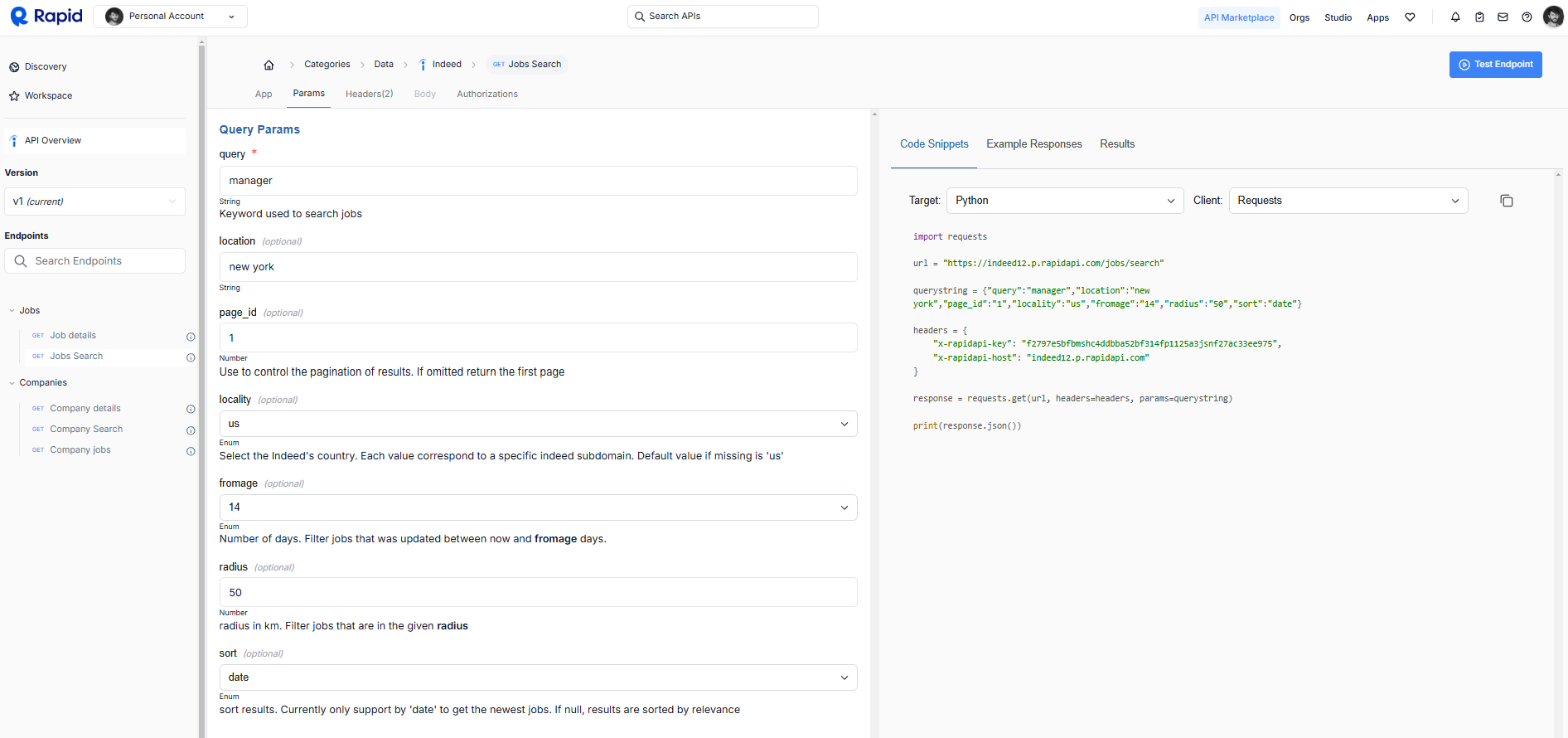
- Open the Params Tab: Once you’ve selected Job Search, click on the “Params” tab to access and configure the various search parameters

2.1 Set Up Your Search Parameters
Here are the most helpful settings to customize your job search:
- query: (Required) Keywords to search for job listings. In this example we use "manager".
- location: (Optional) City or region to limit the job search. In this example, "new york" is defined.
- page_id: (Optional) Page number for pagination of results. If omitted, it defaults to the first page.
- locality: (Optional) Country code to target jobs by location. Default is "us" for the United States.
- fromage: (Optional) Number of days since the job posting date. For example, "14" returns jobs posted within the last 14 days.
- radius: (Optional) Search distance from the given location for jobs in kilometers. Defined here is the "50" km. sort: (Optional) Criteria to sort the results. In this example, "date" is used to sort by the posting date.
2.2 Looking at the Generated Code
On the right side of the screen, you will automatically generate a sample code snippet based on the parameters you have selected. The code shows how to make a basic Python API request using the specified search settings.
2.3 Example Code
Replace the "x-rapidapi-key" value with your actual API key and customize the parameters as needed. Save this code:
import requests
url = "https://indeed12.p.rapidapi.com/jobs/search"
querystring = {"query":"manager","location":"chicago","page_id":"1","locality":"us","fromage":"1","radius":"50","sort":"date"}
headers = {
"x-rapidapi-key": "f2797e5bfbmshc4ddbba52bf314fp1125a3jsnf27ac33ee975",
"x-rapidapi-host": "indeed12.p.rapidapi.com"
}
response = requests.get(url, headers=headers, params=querystring)
print(response.json())2.4 Run the Code and Review the Job Details API Response
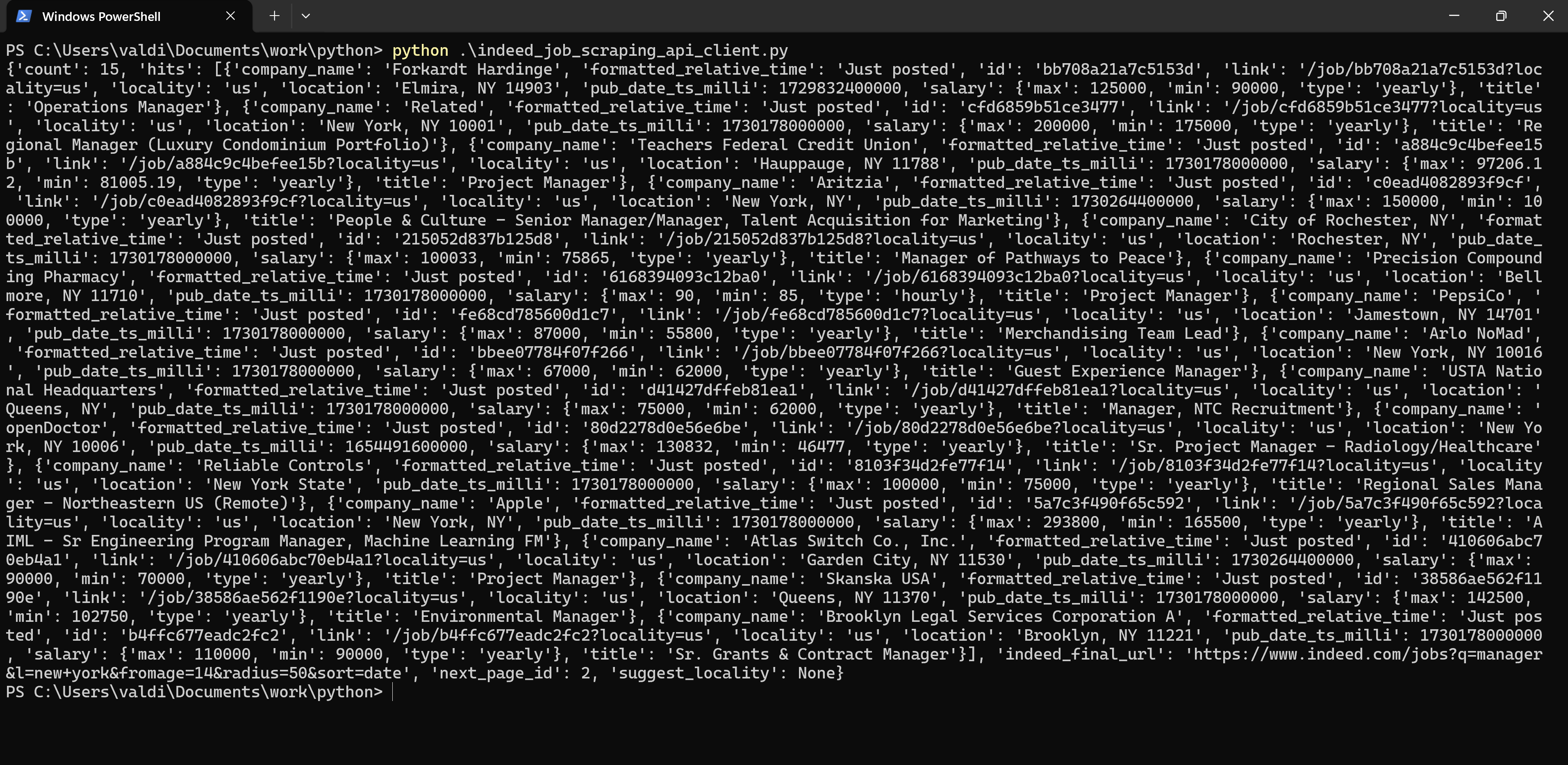
The API returned a JSON response containing job listings based on the specified search parameters. Each listing contains the job position.
This response contains:
Count of Jobs: The quantity of total jobs returned in this response, equal to one Indeed results page with 15 job postings.
Job Details: The following information is given for each job:
- Company Name: The company's name that is posting the job.
- Location: City and state where the job is located.
- Title: Job title (e.g., "Operations Manager," "Project Manager").
- Link: A link to the job posting on Indeed's website.
- Salary: Salary range, including maximum and minimum values, if available.
- Job Type: The type of job, whether "yearly" for salaried or "hourly.".
- Posting Date: Info on how recently the job was posted ("Just posted").
- Job ID: Unique identifier number for each posted job.
The API returns jobs in pages (15 listings per page here), so you’ll need to handle pagination by adjusting the page_id parameter in each request to retrieve all job listings for your search.
Step 3 : Handling Pagination to Retrieve All Job Listings and Export Job Data to CSV format
You'll need to handle pagination in order to retrieve all job listings that match your search criteria. API results are returned in pages that contain 15 job listings each, and you need to change the page_id parameter for every next page until results are exhausted.
API response stores the job listings under the key hits. We will extract data from this key for each page, compile it into a list, and then convert it into a DataFrame for easy handling.
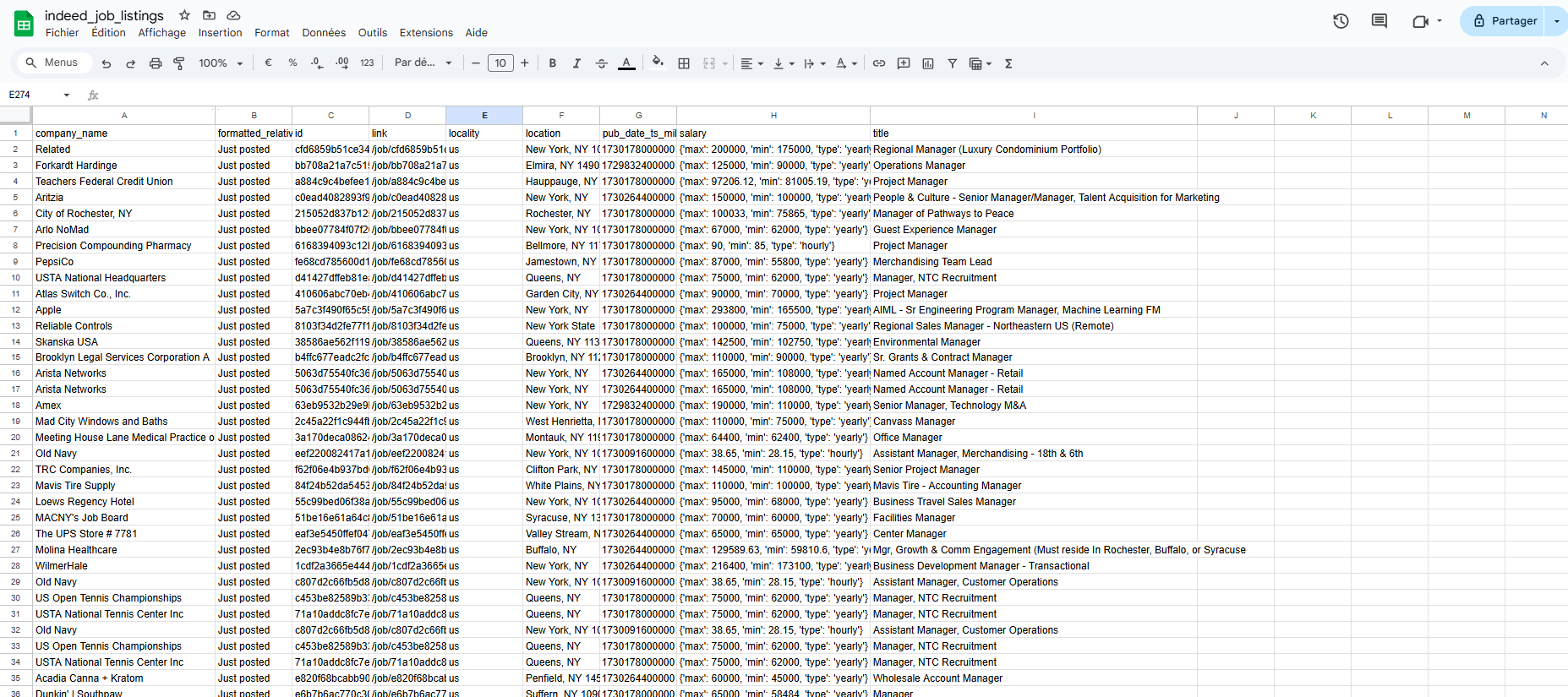
Finally, we will export the job data to a CSV file indeed_job_listings.csv for easy access and analysis.
Here is the code for pagination and exporting the Indeed Job results:
import requests
import pandas as pd
url = "https://indeed12.p.rapidapi.com/jobs/search"
headers = {
"x-rapidapi-key": "f2797e5bfbmshc4ddbba52bf314fp1125a3jsnf27ac33ee975", # Replace with your API key
"x-rapidapi-host": "indeed12.p.rapidapi.com"
}
# Define search parameters
query_params = {
"query": "manager",
"location": "new york",
"locality": "us",
"fromage": "14",
"radius": "50",
"sort": "date",
"page_id": 1 # Start from the first page
}
# Initialize an empty list to store job data
all_jobs = []
# Loop through pages until no more data is returned
while True:
response = requests.get(url, headers=headers, params=query_params)
data = response.json()
# Check if there are job listings in the 'hits' field
if 'hits' in data and data['hits']:
all_jobs.extend(data['hits']) # Add jobs to the list
query_params["page_id"] += 1 # Move to the next page
else:
break # Stop if no more job listings are returned
# Convert the list of job data to a DataFrame and export to CSV
df = pd.DataFrame(all_jobs)
df.to_csv("indeed_job_listings.csv", index=False)
print(f"Total jobs retrieved: {len(all_jobs)}")Result and Conclusion
The Result
We successfully retrieved all job listings matching our search criteria in our CSV file, totaling 270 job offers!
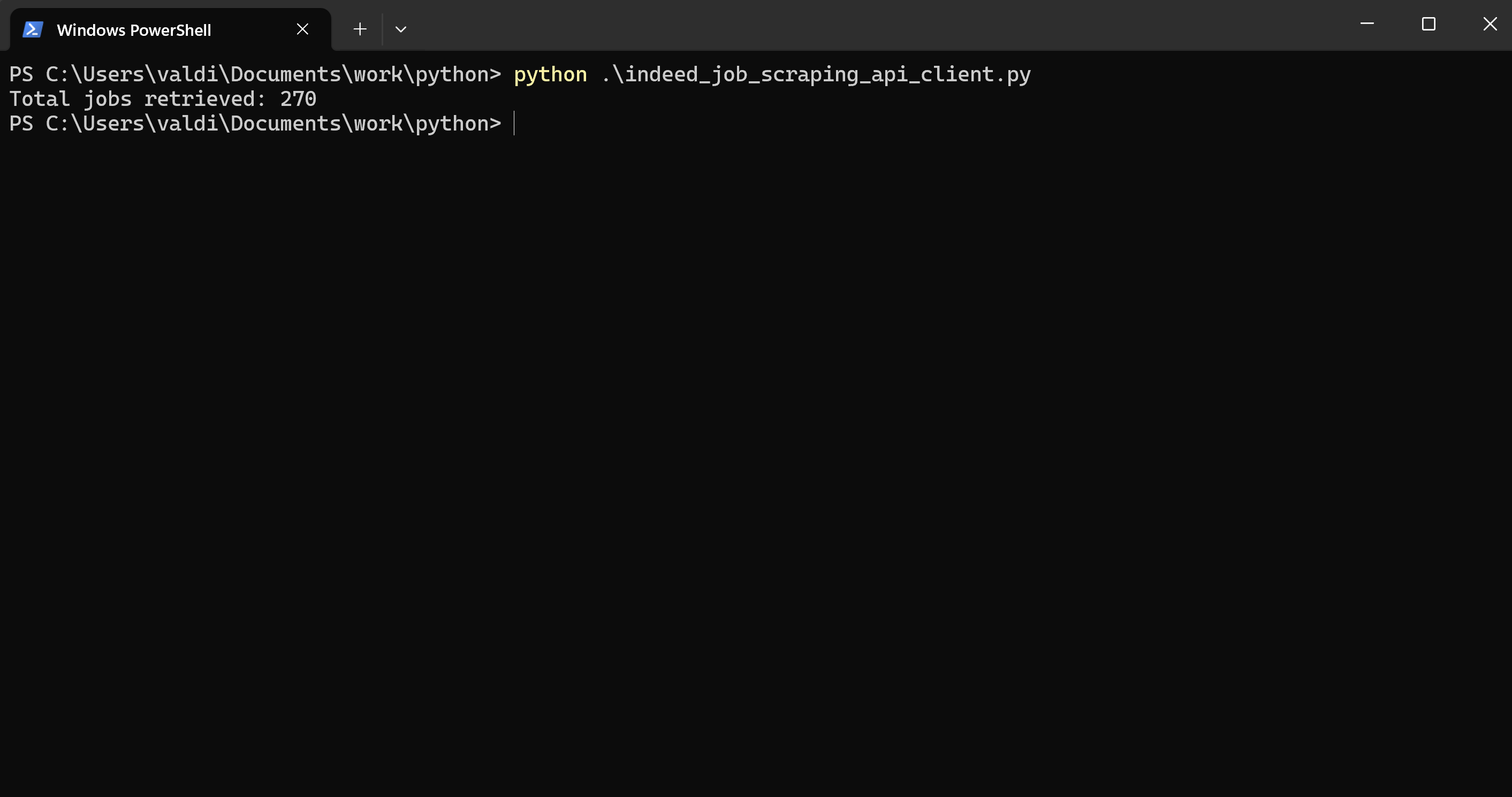
The code made 18 requests to gather these listings, since there are 15 job offers per page.
Final Thoughts
Now, with this step-by-step guide, you have a fully working Indeed job scraper able to collect job listings in consideration of defined criteria and, at the same time, directly export them into a CSV file. This makes the lead generation, market analysis, and competitive tracking really easy.
You can easily adapt or expand the setup to higher data needs as they grow, which makes it a versatile solution for various job data applications.
For a more comprehensive solution, consider the next logical step: collecting contact information for the hiring managers behind these listings.
Happy scraping, and feel free to explore additional configurations or parameters to further customize your Indeed job scraper!
Curious about Job board scraping ? Our guide walks you through the essential methods and tools to help you get started.
FAQ on Scraping Indeed
Why Scrape Indeed.com?
Scraping Indeed provides instant access to job listings, helping analyze trends, skills demand, and qualifications, without the need to search manually.
Is web scraping Indeed.com legal?
Yes, if you comply with the law. Read more about legal job scraping in our article.
What does Indeed Scraper do?
An Indeed scraper scrapes job details, including job titles, companies, locations, and salaries, based on your search parameters for easy tracking and analysis.
How many results can be scraped using this Indeed scraper?
You can get more than 1000 results per day, based on the search settings. The free API limit supports moderate data needs, with upgrade options for more data.
About the author

Alexandre Chirié
CEO of Mantiks
Alexandre Chirié is the co-founder and CEO of Mantiks. With a strong engineering background from Centrale, Alexandre has specialized in job postings data, signal identification, and real-time job market insights. His work focuses on reducing time-to-hire and improving recruitment strategies by enabling access to critical contact information and market signals.